Back in August, at the Firefox Summit, I promised Giorgio Maone to properly analyze NoScript. Trust me, better that than the alternative. And it is not that I forgot. I tried, really. Problem is, Giorgio isn’t a big friend of modularization. Most of NoScript code is contained in two files, one being 2000 and the other whooping 8000 lines long, all of its 500 features nicely intertwined. He isn’t a big fan of documentation either, keeping code comments to a minimum as to prevent code bloat. Finally, he isn’t a big fan of consistency and made sure that each feature is triggered only under its very unique conditions. In short, the code is a mess.
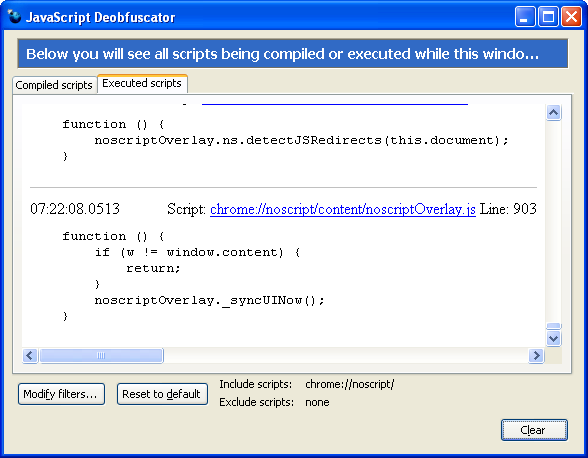
Fortunately, I now have a nice tool for just these cases. On the train from FOSDEM I added the ability to change filters to JavaScript Deobfuscator and worked around bug 475334 to make sure all scripts being executed really show up. It turned out that this isn’t quite enough, XPCOM components are apparently invisible to the debugger and still don’t show up. But at least now I can open JavaScript Deobfuscator, adjust the filters to include “chrome://noscript/” while not excluding anything — and next time I load a page I see exactly what NoScript is doing on page load. There are quite a few things going on there but it is still a lot easier to get an overview than by looking at the source code.
Which brings us to the quiz part of this blog post. Some of the things that NoScript is doing can produce rather interesting effects. For example, who can guess why this page hangs up Firefox for 20 seconds when NoScript is enabled but loads in no time without NoScript? Hint: it has something to do with the awfully long scroll bar on the right that appears when NoScript is enabled.
Comments
That was an interesting little puzzle.
It took quite a bit more than 20 seconds on my somewhat obsolete machine, and Firefox wanted a reminder from me to continue running the script a few times. It was that reminder that gave me puzzle piece #1. Apparently, noscriptService.js was the culprit.
When it was done running the script, Firebug revealed that the page was now filled with a very long, hidden list of anchors. Obviously some overly zealous find-and-replace scheme. Didn’t take very long to discover that the problem lies in the function detectJSRedirects().
const findURL = /(?:(?:\b(?:open|replace)\s*\(|(?:\b(?:href|location|src|path|pathname|search)|(?:[Pp]ath|UR[IL]|[uU]r[il]))\s*=)\s*[’”]|[’”](?=https?:\/\/\w|\w*[\.\/\?]))([\?\/\.\w\-%\&][^\s’”]*)/g;
matches any of the thousands of “.AA pairs in the ‘script’. I’m terrible at reading regexp, so I’m not even sure exactly what it’s supposed to do. ;)
Love reading your blog, BTW. You’re obviously passionate about what you do, and it shows. Kudos!
you should wait for version 2.0 before to investigate more I think. Maybe the code will be more organized…
Else, nice example. :P
That way I’ll risk waiting forever – no, thanks. I will better analyze the version that millions of people are using already.
@Wladimir:
BTW, have you got any idea of why Venkman is so random in detecting JS components? I’ve got profiles where I can somehow debug them, and profile where they are totally invisible :-k
@Haploid:
That’s the JS redirect detection feature (introduced by request of Josh Soref AKA timeless), which scans script elements on script-disabled and link-less pages to find if they would try to automatically navigate user if JavaScript was enabled. This come quite handy on many silly empty pages which just redirect you to the “real” content using JavaScript.
Of course, like JavaScript itself and many other browser-built-in features, some NoScript’s features (and probably some AdBlock Plus’ as well) can be abused for “DOS” purposes, but fortunately since we’re still JavaScript you can halt the loop after a while.
I doubt you want to make that regexp more strict about what it considers to be a link. But it would probably help to limit the number of detected “links” ;)
Or at least use hash tables to detect duplicates. And use nsIIOService.newURI() to resolve relative links rather than insert a link element into the document only to remove it immediately (not exactly a cheap operation).
Oh, and about JS components – no, I have no idea but it is the same reason that prevents JavaScript Deobfuscator from seeing them. I want to look into this, will try to find out or at least file a bug on it (though this seems to be pointless, nobody cares about the debugger interfaces).
@Wladimir
Putting an upper limit to the links will surely help. Resolving relative URIs without depending on the DOM would be nice too, even though I never considered this feature performance-sensitive, since it should be triggered on an almost negligible number of pages and anyway whatever you do performance-wise (upper limits aside) can’t eliminate DOS issues.
Regarding the debugger interfaces, doesn’t (Fire|Chrome)Bug depend on them?
Of course they do, see bug 449452.
You were at FOSDEM?! I was there on Sunday. It would have been an honour to shake your hand.