Xunlei Accelerator (迅雷客户端) a.k.a. Xunlei Thunder by the China-based Xunlei Ltd. is a wildly popular application. According to the company’s annual report 51.1 million active users were counted in December 2022. The company’s Google Chrome extension 迅雷下载支持, while not mandatory for using the application, had 28 million users at the time of writing.
I’ve found this application to expose a massive attack surface. This attack surface is largely accessible to arbitrary websites that an application user happens to be visiting. Some of it can also be accessed from other computers in the same network or by attackers with the ability to intercept user’s network connections (Man-in-the-Middle attack).
It does not appear like security concerns were considered in the design of this application. Extensive internal interfaces were exposed without adequate protection. Some existing security mechanisms were disabled. The application also contains large amounts of third-party code which didn’t appear to receive any security updates whatsoever.
I’ve reported a number of vulnerabilities to Xunlei, most of which allowed remote code execution. Still, given the size of the attack surface it felt like I barely scratched the surface.
Last time Xunlei made security news, it was due to distributing a malicious software component. Back then it was an inside job, some employees turned rouge. However, the application’s flaws allowed the same effect to be easily achieved from any website a user of the application happened to be visiting.
I decided that I would make it easier for people to share my articles on social media, most importantly on Mastodon. However, my Hugo theme didn’t support showing a “Share on Mastodon” button yet. It wasn’t entirely trivial to add support either: unlike with centralized solutions like Facebook where a simple link is sufficient, here one would need to choose their home instance first.
As far as existing solutions go, the only reasonably sophisticated approach appears to be Share₂Fedi. It works nicely, privacy-wise one could do better however. So I ended up implementing my own solution while also generalizing that solution to support a variety of different Fediverse applications in addition to Mastodon.
In September last year, a breach at LastPass’ parent company GoTo (formerly LogMeIn) culminated in attackers siphoning out all data from their servers. The criticism from the security community has been massive. This was not so much because of the breach itself, such things happen, but because of the many obvious ways in which LastPass made matters worse: taking months to notify users, failing to provide useful mitigation instructions, downplaying the severity of the attack, ignoring technical issues which have been publicized years ago and made the attackers’ job much easier. The list goes on.
Now this has been almost a year ago. LastPass promised to improve, both as far as their communication goes and on the technical side of things. So let’s take a look at whether they managed to deliver.
TL;DR: They didn’t. So far I failed to find evidence of any improvements whatsoever.
Update (2023-09-26): It looks like at least the issues listed under “Secure settings” are finally going to be addressed.
Five years ago I wrote an article about the shortcomings of Chrome Sync (as well as a minor issue with Firefox Sync). Now Chrome Sync has seen many improvements since then. So time seems right for me to revisit it and to see whether it respects your privacy now.
Spoiler: No, it doesn’t. It improved, but that’s an improvement from outright horrible to merely very bad. The good news: today you can use Chrome Sync in a way that preserves your privacy. Google however isn’t interested in helping you figure out how to do it.
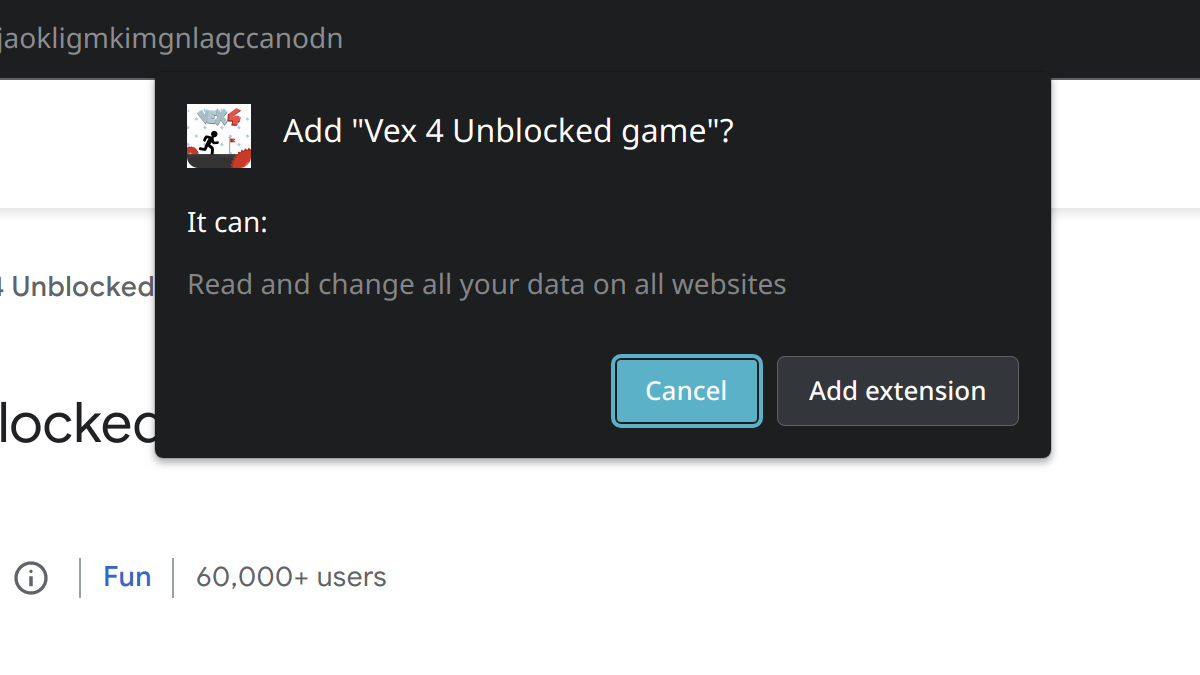
When installing browser extensions in Google Chrome, you are asked to confirm the extension’s permissions. In theory, this is supposed to allow assessing the risk associated with an extension. In reality however, users typically lack the knowledge to properly interpret this prompt. For example, I’ve often seen users accusing extension developers of spying just because the prompt says they could.
On the other hand, people will often accept these cryptic prompts without thinking twice. They expect the browser vendors to keep them out of harm’s way, trust that isn’t always justified [1][2][3]. The most extreme scenario here is casual games not interacting with the web at all, yet requesting access to all websites. I found a number of extensions that will abuse this power to hijack websites.
We’ve already seen Chrome extensions containing obfuscated malicious code. We’ve also seen PCVARK’s malicious ad blockers. When looking for more PCVARK extensions, I stumbled upon an inconspicuous extension called “Translator - Select to Translate.” The only unusual thing about it were its reviews, lots of raving positive reviews mixed with usability complains. That, and the permissions: why does a translator extension need webRequest and webRequestBlocking permissions?
When I looked into this extension, I immediately discovered a strange code block. Supposedly, it was buggy locale processing. In reality, it turned out to be an obfuscated malicious logic meant to perform affiliate fraud.
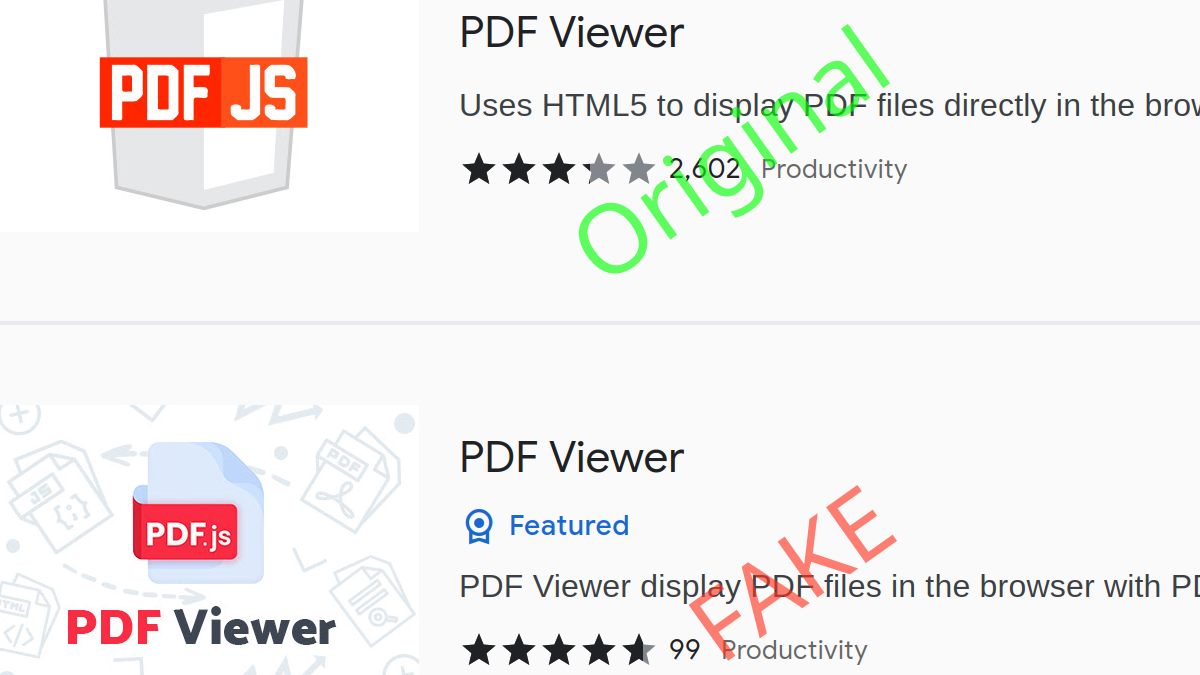
That extension wasn’t alone. I kept finding similar extensions until I had a list of 109 extensions, installed by more than 62 million users in total. While most of these extensions didn’t seem to contain malicious code (yet?), almost all of them requested excessive privileges under false pretenses. The names are often confusingly similar to established products. All of these extensions are clearly meant for dubious monetization.
If you aren’t interested in the technical details, you should probably go straight to the list of affected extensions.
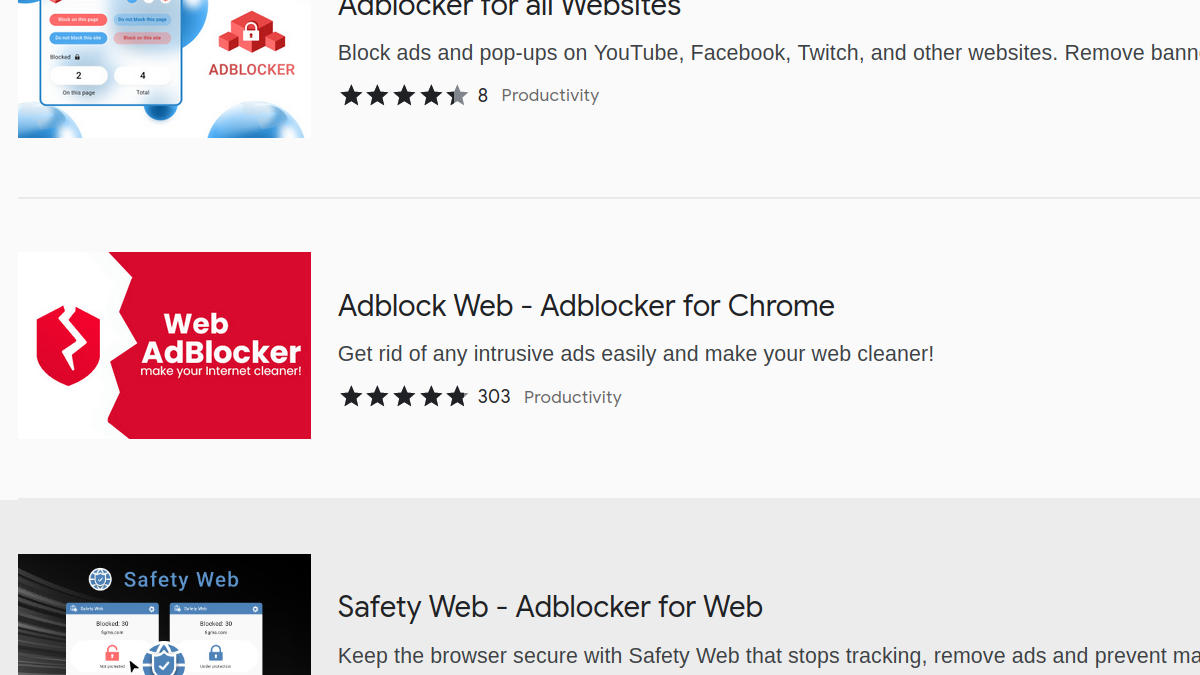
It isn’t news that the overwhelming majority of ad blockers in Chrome Web Store is either outright malicious or waiting to accumulate users before turning malicious. So it wasn’t a surprise that the very first ad blocker I chose semi-randomly (Adblock Web with 700,000 users) turned out malicious. Starting from it, I found another malicious extension (Ad-Blocker, 700,000 users) and two more that have been removed from Chrome Web Store a year ago (BitSafe Adblocker and Adblocker Unlimited).
All these ad blockers and probably some more were developed by the company PCVARK. According to Malwarebytes Labs, this company specializes in developing “potentially unwanted programs.” In other words: they show users warnings about alleged compromise, only to push them into installing their software. Once installed, this software will attempt to scare the user into installing more crappy applications and into paying money for fixing the supposed issue.
While PCVARK originally specialized in Mac software, they apparently also discovered pushing malicious ad blockers to Chrome Web Store as a valuable business opportunity. This was encouraged by Google’s lax moderation policies as well an almost complete lack of policy enforcement. While Google eventually managed to remove some extensions, at least two remain despite being obviously related to the removed ones.
Update (2023-06-12): The complete list of extension IDs from this article series can be found here. This repository also contains the check-extensions command-line utility which will search local browser profiles for these extensions.
Two days ago I wrote about the malicious extensions I discovered in Chrome Web Store. At some point this article got noticed by Avast. Once their team confirmed my findings, Google finally reacted and started removing these extensions. Out of the 34 extensions I reported, only 8 extensions remain. These eight were all part of an update where I added 16 extensions to my list, an update that came too late for Avast to notice.
Note: Even for the removed extensions, it isn’t “mission accomplished” yet. Yes, the extensions can no longer be installed. However, the existing installations remain. From what I can tell, Google didn’t blocklist these extensions yet.
Avast ran their own search, and they found a bunch of extensions that I didn’t see. So how come they missed eight extensions? The reason seems to be: these are considerably different. They migrated to Manifest V3, so they had to find new ways of running arbitrary code that wouldn’t attract unnecessary attention.
Update (2023-06-03): These extensions have been removed from the Chrome Web Store as well.
Update (2023-06-12): The complete list of extension IDs from this article series can be found here. This repository also contains the check-extensions command-line utility which will search local browser profiles for these extensions.
Two weeks ago I wrote about the PDF Toolbox extension containing obfuscated malicious code. Despite reporting the issue to Google via two different channels, the extension remains online. It even gained a considerable number of users after I published my article.
A reader tipped me off however that the Zoom Plus extension also makes a request to serasearchtop[.]com. I checked it out and found two other versions of the same malicious code. And I found more extensions in Chrome Web Store which are using it.
So now we are at 18 malicious extensions with a combined user count of 55 million. The most popular of these extensions are Autoskip for Youtube, Crystal Ad block and Brisk VPN: nine, six and five million users respectively.
Update (2023-06-01): With an increased sample I was able to find some more extensions. Also, Lukas Andersson did some research into manipulated extension ratings in Chrome Web Store and pointed out that other extensions exhibited similar patterns in their review. With his help I was able to identify yet another variant of this malicious code and a bunch more malicious extensions. So now we are at 34 malicious extensions and 87 million users.
Update (2023-06-02): All but eight of these extensions have been removed from Chrome Web Store. These eight extensions are considerably different from the rest, so I published a follow-up blog post discussing the technical aspects here.
The PDF Toolbox extension for Google Chrome has more than 2 million users and an average rating of 4,2 in the Chrome Web Store. So I was rather surprised to discover obfuscated code in it that has apparently gone unnoticed for at least a year.
The code has been made to look like a legitimate extension API wrapper, merely with some convoluted logic on top. It takes a closer look to recognize unexpected functionality here, and quite some more effort to understand what it is doing.
This code allows serasearchtop[.]com website to inject arbitrary JavaScript code into all websites you visit. While it is impossible for me to tell what this is being used for, the most likely use is injecting ads. More nefarious uses are also possible however.
Update (2023-06-12): The complete list of extension IDs from this article series can be found here. This repository also contains the check-extensions command-line utility which will search local browser profiles for these extensions.