These days it’s typical for antivirus vendors to provide you with a browser extension which is meant to improve your online security. I’ll say up front: I don’t consider any such browser extensions recommendable. At best, they are worthless. At worst, they introduce massive security issues.
As an example I took a brief look at the Online Security extension by ReasonLabs. No, there is no actual reason beyond its 7 million users. I think that this extension is a fairly typical representative of its craft.
TL;DR: Most Online Security functionality is already provided by the browser, and there is little indication that it can improve on that. It does implement its functionality in a maximally privacy-unfriendly way however, sharing your browsing history and installed extensions with the vendor. There is also plenty of sloppy programming, some of which might potentially cause issues.
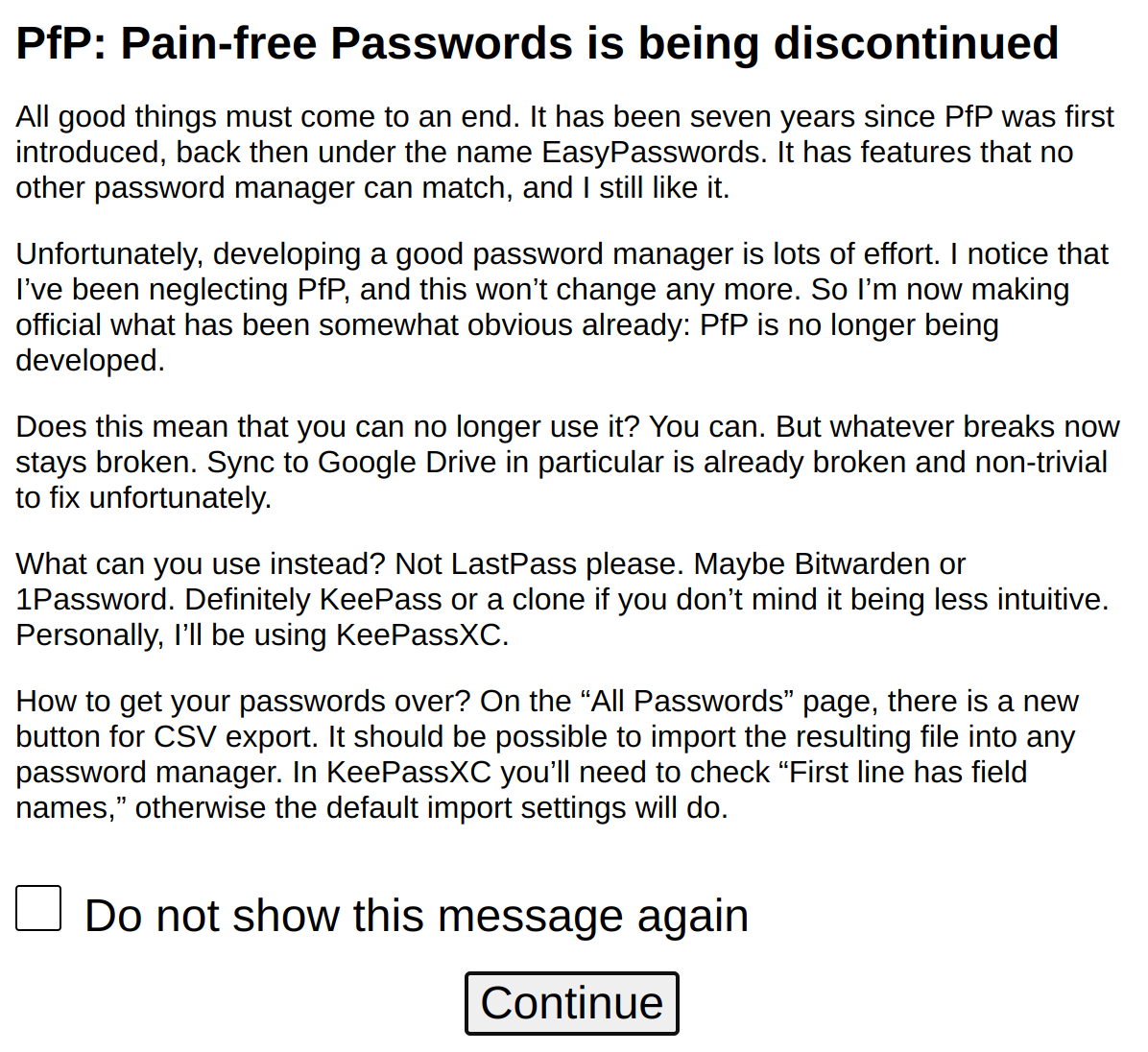
A month ago I announced the end of PfP: Pain-free Passwords. But I’m allowed to change my mind, right? Yes, PfP will be developed further after all. However, it’s so different that I’m publishing it as a new browser extension, not an update to the existing extension.
Rather than using its own data format, PfP 3.x reads and writes KeePass database files. In order for the extension to access these files, users have to install a PfP Native Host application. This application provides access to the configured database files only.
Also, PfP 3.x no longer generates passwords on the fly. All passwords are stored inside the database, and generating passwords randomly happens when passwords are added. While this makes recovery more complicated, elsewhere it simplifies things a lot.
I am by no means a Rust expert, and I’m no expert on declarative macros. I was merely solving an issue I had: there was a lot of redundancy in the way my error types were coded. I didn’t want to repeat the same coding patterns all the time, yet the types also seemed too heterogenous for declarative macros. And going with procedural macros wasn’t worth the effort in this case.
After some experimentation I figured out how declarative macros could work in this scenario after all. I doubt that this approach is very original, and maybe I solved something in a sub-optimal way. I couldn’t find any helpful online sources however, which is why I’m documenting this in my own article. Edit: After publishing this article, I found that the pattern used here is called TT munching.
I’ve been playing around with KeePass databases. One aspect was rather surprising: given how many open source products use this format, it is remarkably underdocumented. At best, you can find outdated and incomplete descriptions by random people. The KeePass developers themselves never bothered providing complete documentation. All you get is a semi-intelligible list of changes from KDBX 3.1 to KDBX 4 and from KDBX 4 to KDBX 4.1. With the starting point not being documented, these are only moderately useful.
And so it’s not surprising that the implementations I looked at aren’t actually implementing the same file format. They all probably manage to handle common files in the same way, but each of them has subtle differences when handling underdocumented format features.
I’ll try to explain the format and the subtle details here. For that, I looked at the source code of KeePass, KeePassXC, keepass-rs Rust library and the kxdbweb JavaScript library. Let’s hope this documentation helps whoever else needs to work with that file format, and studying source code will no longer be required.
I can only document the latest version of the format (KDBX 4.1), though I’ll try to highlight changes wherever I’m aware of them.
Seven years ago I created a password manager. And a few days ago I pushed out the last release for it, notifying users that nothing else will come now. Yes, with the previous release being from 2019, this might have been obvious. Now it’s official however, PfP: Pain-free Passwords is no longer being developed.
I certainly learned a lot from this adventure, and I really like the product which came out of this. Unfortunately, a password manager is a rather time-consuming hobby, and my focus has been elsewhere for a while already.
This doesn’t mean that PfP is going away. In fact, it will probably work well for quite a while until a browser change or something like that makes it unusable. Sync functionality in particular depends on third parties however, and this one already started falling apart.
This little adventure began with me being annoyed at DMARC aggregate reports. My domain doesn’t have enough email traffic to justify routing DMARC emails to some third-party analytics service, yet I want to take a brief glance at them. And the format of these emails makes that maximally inconvenient: download the attachment, unpack it, look through some (always messy but occasionally not even human-readable) XML code. There had to be a better way.
This could have been a Thunderbird extension, processing the email attachment in order to produce some nicer output. Unfortunately, Thunderbird extensions no longer have this kind of power. So I went for another option: having the email server (OpenSMTPD) convert the email as it comes in.
Since I already had the implementation details of OpenSMTPD filters figured out, this wasn’t as complicated as it sounds. The resulting code is on GitHub but I still want to document the process for future me and anyone else who might have a similar issue.
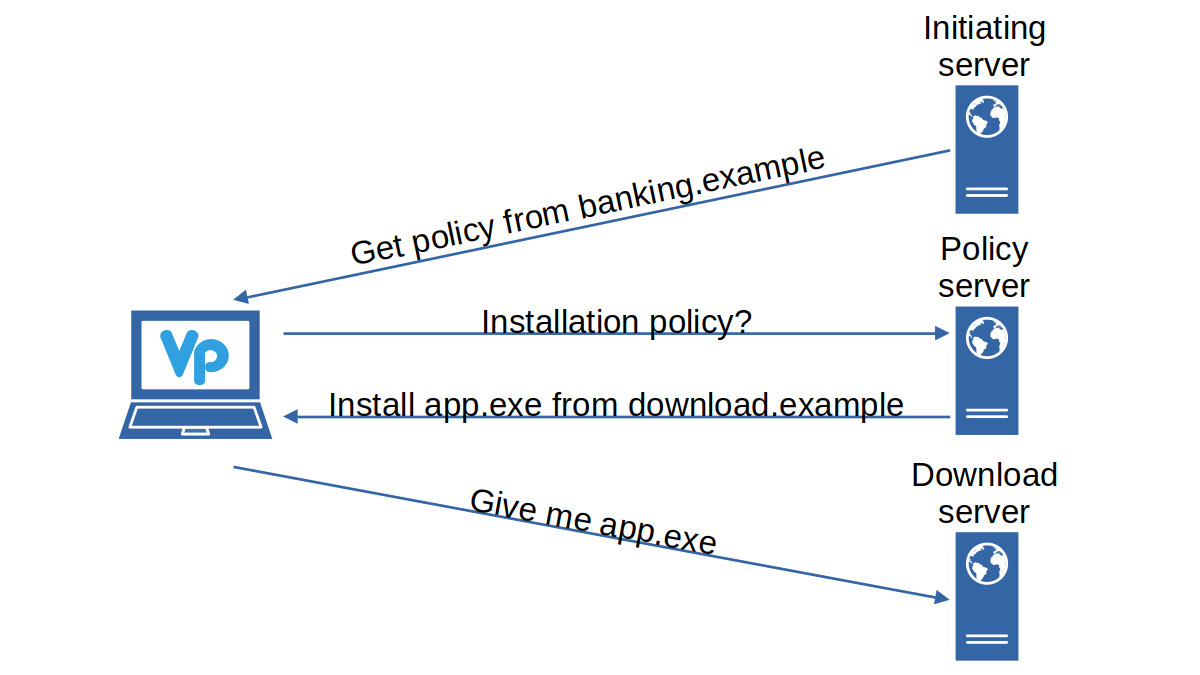
And that’s only two applications. Korea’s banking websites typically expect around five applications, and it will be different applications for different websites. That’s a lot of applications to install and to keep up-to-date.
Luckily, the Veraport application by Wizvera will take care of that. This application will automatically install everything necessary to use a particular website. And it will also install updates if deemed necessary.
Back then everybody was quick to shift the blame to the compromised web servers. I now took a deeper dive into how Veraport works and came to the conclusion: its approach is inherently dangerous.
As of Veraport 3.8.6.5 (released on February 28), all the reported security issues seem to be fixed. Getting users to update will take a long time however. Also, the dangerous approach of allowing Veraport customers to distribute arbitrary software remains of course.
Half a year after the LastPass breach started in August 2022, information on it remains sparse. It took until December 2022 for LastPass to admit losing their users’ partially encrypted vault data. This statement was highly misleading, e.g. making wrong claims about the protection level provided by the encryption. Some of the failures to protect users only became apparent after some time, such as many accounts configured with a dangerously low password iterations setting, the company hasn’t admitted them to this day.
Despite many questions being raised, LastPass maintained strict radio silence since December. Until yesterday they published an article with details of the breach. If you were hoping to get answers: nope. If you look closely, the article again carefully avoids making definitive statements. There is very little to learn here.
TL;DR: The breach was helped by a lax security policy, an employee was accessing critical company data from their home computer. Also, contrary to what LastPass claimed originally, business customers using Federated Login Services are very much affected by this breach. In fact, the attackers might be able to decrypt company data without using any computing resources on bruteforcing master passwords.
Update (2023-02-28): I found additional information finally explaining the timeline here. So the breach affects LastPass users who had an active LastPass account between August 20 and September 16, 2022. The “Timeline of the breach” section has been rewritten accordingly.
The most important question is: all the security issues and bad practices aside, does this approach to banking security make sense? Do these applications have the potential to make people more secure when rolled out mandatorily nation-wide?
TL;DR: I think that the question above can be answered with a clear “no.” The approaches make little sense given actual attack scenarios, they tend to produce security theater rather than actual security. And while security theater can sometimes be useful, the issues in question have proper solutions.
I recently switched from VirtualBox to KVM for my virtualization needs. While this approach has clear advantages such as not requiring custom kernel drivers, the downside is that snapshots aren’t currently supported for Windows 11. And since I don’t want applications I analyze to corrupt my main Windows VM, I decided that I should run these in freshly created Windows VMs.
The issue with this approach is: setting up a new Windows VM is fairly time-consuming. Not only is it necessary to answer a number of questions during installation, installing the proper guest tools for KVM is non-trivial as well. And I also rely on some further applications for my work.
Luckily, Windows installation supports answer files which make this task far easier. With the right answer file and some scripts, setting up a Windows VM is a fully automated task that takes half an hour and none of my attention. The necessary information was rather scattered and often outdated, so I decided to put it all into one blog post.
![Message on www.citibank.co.kr stating: [IP Logger] program needs to be installed to ensure safe use of the service. Do you want to move to the installation page?](/2023/02/20/south-koreas-banking-security-intermediate-conclusions/message.png)