Normally, when you navigate to your bank’s website you have little reason to worry about impersonations. The browser takes care of verifying that you are really connected to the right server, and that your connection is safely encrypted. It will indicate this by showing a lock icon in the address bar.
So even if you are connected to a network you don’t trust (such as open WiFi), nothing can go wrong. If somebody tries to impersonate your bank, your browser will notice. And it will refuse connecting.
This is achieved by means of a protocol called Transport Layer Security (TLS). It relies on a number of trusted Certification Authorities (CAs) to issue certificates to websites. These certificates allow websites to prove their identity.
When investigating South Korea’s so-called security applications I noticed that all of them add their own certification authorities that browsers have to trust. This weakens the protection provided by TLS considerably, as misusing these CAs allows impersonating any website towards a large chunk of South Korean population. This puts among other things the same banking transactions at risk that these applications are supposed to protect.
The conclusion of my blog posts on the LastPass breach and on Bitwarden’s design flaws is invariably: a strong master password is important. This is especially the case if you are a target somebody would throw considerable resources at. But everyone else might still get targeted due to flaws like password managers failing to keep everyone on current security settings.
There is lots of confusion about what constitutes a strong password however. How strong is my current password? Also, how strong is strong enough? These questions don’t have easy answers. I’ll try my best to explain however.
If you are only here for recommendations on finding a good password, feel free to skip ahead to the Choosing a truly strong password section.
On our tour of South Korea’s so-called security applications we’ve already took a look at TouchEn nxKey, an application meant to combat keyloggers by … checks notes … making keylogging easier. Today I want to shed some light on another application that many people in South Korea had to install on their computers: IPinside LWS Agent by Interezen.
The stated goal of the application is retrieving your “real” IP address to prevent online fraud. I found however that it collects way more data. And while it exposes this trove of data to any website asking politely, it doesn’t look like it is all too helpful for combating actual fraud.
In the aftermath of the LastPass breach it became increasingly clear that LastPass didn’t protect their users as well as they should have. When people started looking for alternatives, two favorites emerged: 1Password and Bitwarden. But do these do a better job at protecting sensitive data?
For 1Password, this question could be answered fairly easily. The secret key functionality decreases usability, requiring the secret key to be moved to each new device used with the account. But the fact that this random value is required to decrypt the data means that the encrypted data on 1Password servers is almost useless to potential attackers. It cannot be decrypted even for weak master passwords.
As to Bitwarden, the media mostly repeated their claim that the data is protected with 200,001 PBKDF2 iterations: 100,001 iterations on the client side and another 100,000 on the server. This being twice the default protection offered by LastPass, it doesn’t sound too bad. Except: as it turns out, the server-side iterations are designed in such a way that they don’t offer any security benefit. What remains are 100,000 iterations performed on the client side, essentially the same protection level as for LastPass.
Edit (2023-01-23): Bitwarden increased the default client-side iterations to 350,000 a few days ago. So far this change only applies to new accounts, and it is unclear whether they plan to upgrade existing accounts automatically. And today OWASP changed their recommendation to 600,000 iterations, it has been adjusted to current hardware.
Edit (2023-01-24): I realized that some of my concerns were already voiced in Bitwarden’s 2018 Security Assessment. Linked to it in the respective sections.
Update (2023-01-16): This article is now available in Korean.
I wrote about South Korea’s mandatory so-called security applications a week ago. My journey here started with TouchEn nxKey by RaonSecure which got my attention because the corresponding browser extension has more than 10 million users – the highest number Chrome Web Store will display. The real number of users is likely considerably higher, the software being installed on pretty much any computer in South Korea.
That’s not because people like it so much: they outright hate it, resulting in an average rating of 1,3 out of 5 stars and lots of calls to abolish it. Yet using it is required if you want to do things like online banking in South Korea.
The banks pushing for the software to be installed claim that it improves security. People call it “malware” and a “keylogger.” I spent some time analyzing the inner workings of the product and determined the latter to be far closer to the truth. The application indeed contains key logging functionality by design, and it fails to sufficiently restrict access to it. In addition, various bugs range from simple denial of service to facilitating remote code execution. Altogether I reported seven security vulnerabilities in the product.
Edit (2023-01-04): A Korean translation of this article is now available here, thanks to Woojin Kim. Edit (2023-01-07): Scheduled one more disclosure for February.
Last September I started investigating a South Korean application with unusually high user numbers. It took me a while to even figure out what it really did, there being close to zero documentation. I eventually realized that the application is riddled with security issues and, despite being advertised as a security application, makes the issue it is supposed to address far, far worse.
That’s how my journey to the South Korea’s very special security application landscape started. Since then I investigated several other applications and realized that the first one wasn’t an outlier. All of them caused severe security and privacy issues. Yet they were also installed on almost every computer in South Korea, being a prerequisite for using online banking or government websites in the country.
Before I start publishing articles on the individual applications’ shortcomings I wanted to post a summary of how (in my limited understanding) this situation came about and what exactly went wrong. From what I can tell, South Korea is in a really bad spot security-wise right now, and it needs to find a way out ASAP.
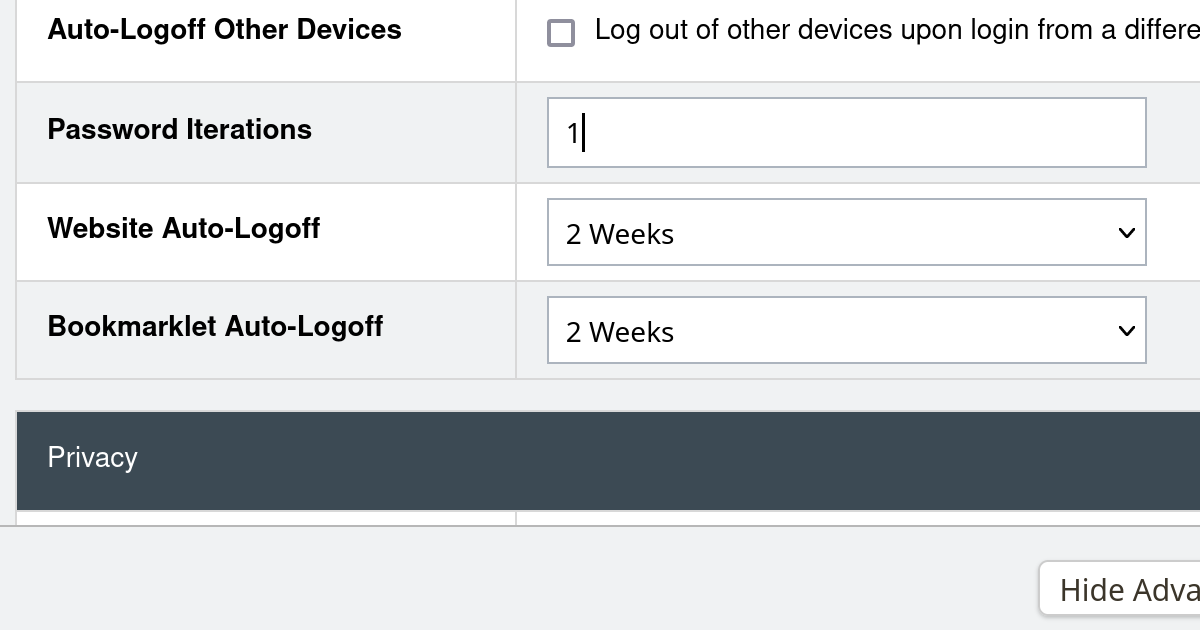
LastPass has been breached, data has been stolen. I already pointed out that their official statement is misleading. I also explained that decrypting passwords in the stolen data is possible which doesn’t mean however that everybody is at risk now. For assessing whether you are at risk, a fairly hidden setting turned out critical: password iterations.
LastPass provides an instruction to check this setting. One would expect it to be 100,100 (the LastPass default) for almost everyone. But plenty of people report having 5,000 configured there, some 500 and occasionally it’s even 1 (in words: one) iteration.
Let’s say this up front: this isn’t the account holders’ fault. It rather is a massive failure by LastPass. They have been warned, yet they failed to act. And even now they are failing to warn the users who they know are at risk.
Right before the holiday season, LastPass published an update on their breach. As people have speculated, this timing was likely not coincidental but rather intentional to keep the news coverage low. Security professionals weren’t amused, this holiday season became a very busy time for them. LastPass likely could have prevented this if they were more concerned about keeping their users secure than about saving their face.
Their statement is also full of omissions, half-truths and outright lies. As I know that not everyone can see through all of it, I thought that I would pick out a bunch of sentences from this statement and give some context that LastPass didn’t want to mention.
A few days ago LastPass admitted that unknown attackers copied their “vault data.” It certainly doesn’t help that LastPass failed to clarify which parts of the vaults are encrypted and which are not. LastPass support adds to the confusion by stating that password notes aren’t encrypted which I’m quite certain is wrong.
In fact, it’s pretty easy to view your own LastPass data. And it shows that barely anything changed since I wrote about their “encrypted vault” myth four years go. Passwords, account and user names, as well as password notes are encrypted. Everything else: not so much. Page addresses are merely hex-encoded and various metadata fields are just plain text.
If you have a LastPass account you should have received an email updating you on the state of affairs concerning a recent LastPass breach. While this email and the corresponding blog post try to appear transparent, they don’t give you a full picture. In particular, they are rather misleading concerning a very important question: should you change all your passwords now?
The following statement from the blog post is a straight-out lie:
If you use the default settings above, it would take millions of years to guess your master password using generally-available password-cracking technology.
This makes it sound like decrypting the passwords you stored with LastPass is impossible. It also prepares the ground for blaming you, should the passwords be decrypted after all: you clearly didn’t follow the recommendations. Fact is however: decrypting passwords is expensive but it is well within reach. And you need to be concerned.
I’ll delve into the technical details below. But the executive summary is: it very much depends on who you are. If you are someone who might be targeted by state-level actors: danger is imminent and you should change all your passwords ASAP. You should also consider whether you still want them uploaded to LastPass servers.
If you are a regular “nobody”: access to your accounts is probably not worth the effort. Should you hold the keys to your company’s assets however (network infrastructure, HR systems, hot legal information), it should be a good idea to replace these keys now.
Unless LastPass underestimated the scope of the breach that is. If their web application has been compromised nobody will be safe. Happy holidays, everyone!
Edit (2022-12-27): As it turned out, even for a “nobody” there are certain risk factors. You should especially check your password iterations setting. LastPass failed to upgrade some accounts from 5,000 to 100,100 iterations. If it’s the former for you, your account has a considerably higher risk of being targeted.
Also, when LastPass introduced their new password complexity requirements in 2018 they failed to enforce them for existing accounts. So if your master password is shorter than twelve characters you should be more concerned about your passwords being decrypted.
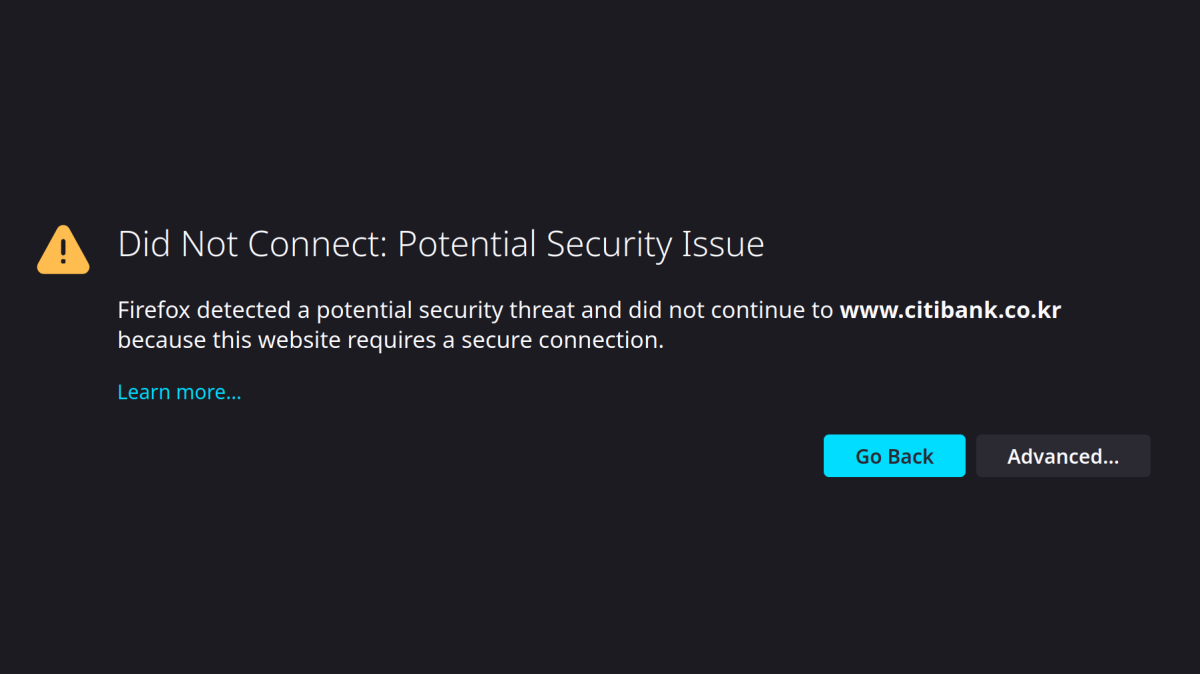
![Message on www.citibank.co.kr stating: [IP Logger] program needs to be installed to ensure safe use of the service. Do you want to move to the installation page?](/2023/01/02/south-koreas-online-security-dead-end/message.png)